Python
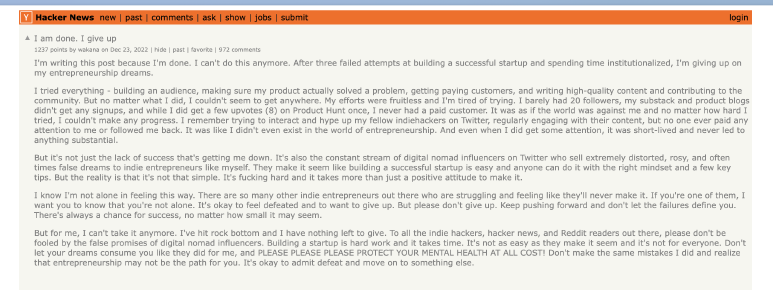
I originally posted this on X as a response to this HackerNews post (full text at the end of this post) but thought its worth expanding on.
Too many people fall in love with the idea of entrepreneurship and all the buzz around it and confuse causation with effect - building somethign new and turning it into a successful venture is effing hard and most likely fail.

We recently switched to Twingate’s GKE load balancer to use Google’s new Container-native load balancer. The premise was good - LB talks directly to pods and saves an extra network hops, (with classic LB, traffic goes from LB to a GKE node which then, based on iptables configured by kube-proxy, get routed to the pod) and should perform better, support more features, and in general we’d rather be on google’s maintained side and not on legacy tech.

One of the most important aspects of building your own analytics system is how you store the data and expose it for querying. This post describes the challenges and approach taken when designing the analytics system for dapPulse (now monday.com) and later at Wondermall.
Problem Definition # Most Analytics software out there lets you define events as an event_name coupled with a bag of data properties.

How to Structure Your PySpark Job Repository and Code
Using PySpark to process large amounts of data in a distributed fashion is a great way to manage large-scale data-heavy tasks and gain business insights while not sacrificing on developer efficiency.
In short, PySpark is awesome. However, while there are a lot of code examples out there, there’s isn’t a lot of information out there (that I could find) on how to build a PySpark codebase— writing modular jobs, building, packaging, handling dependencies, testing, etc.